

有赞 MySQL 自动化运维之路—ZanDB
一、前言
在互联网时代,业务规模常常出现爆发式的增长。快速的实例交付,数据库优化以及备份管理等任务都对 DBA 产生了更高的要求,单纯的凭借记忆力去管理那几十套 DB 已经不再适用。那么如何去批量管理这些实例的备份、元数据、定时脚本和快速实例交付就成了急需解决的的问题。
二、数据库的标准化
在实现 MySQL 的自动化运维的过程中,最痛苦的无非是目录的不统一,配置文件的混乱以及 DB 主机的不标准,而这些不标准的环境会让自动化运维的路途荆棘重重。所以首先我们将相应的 DB 主机以及目录做了标准化,将以前不符合的标准的主机和实例进行改造。
- 一台机子上所有实例,都是在统一的目录下,通过端口进行区分,例如 my3306,my3307。然后在 my3306 下面创建对应的数据目录、日志目录、运行文件目录等
- 每个实例独享一个配置文件,除 server_id , buffer_pool_size 等参数外其他参数保持一致
- 线上环境的 MySQL 软件目录和版本保持一致
三、自动化运维之路一期
在一开始的时候,我们需要着手解决目前的最要紧的事情:备份。对于 DBA 来说,备份重于一切。如果 DBA 对自己维护的数据库的备份情况都一无所知,那么总有一天,你会遭遇数据丢失的灾难。因此,我们开始第一期的工作,ZanDB 备份监控系统。
它实现的主要功能是:
- 实时查看备份的情况,当前应备份实例个数,已完成实例数
- 显示每个备份的耗费时长
- 查看过去 5 天的备份统计信息,如总个数,大小等
四、自动化运维之路二期
在实现了 ZanDB 备份监控系统之后,我们着手开始设计 ZanDB 的二期设计研发工作。
在设计 ZanDB 的过程中,我们将主要功能分成了七部分:备份管理,实例管理,主机管理,任务管理,元数据管理,日志管理,日常维护。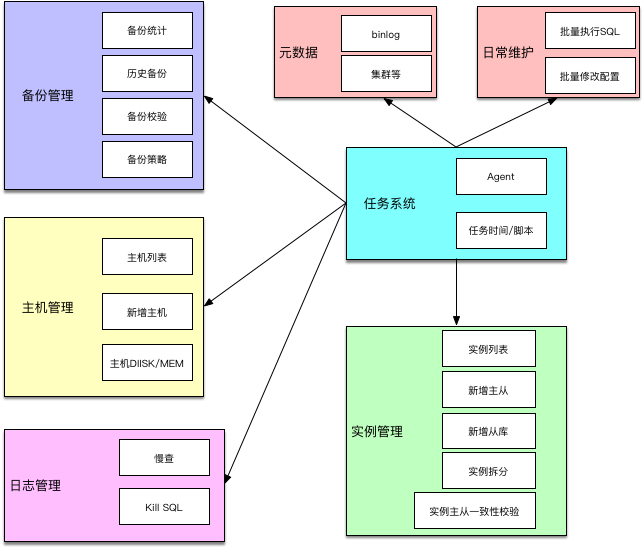
1、任务系统
为了实现实例的备份、元数据、定时脚本等工作,必须要有一个健壮的任务调度系统。该任务系统支持多种类型的任务:每天的定时任务,每个星期的定时任务,每个月的定时任务,还支持一定间隔的重复性任务。
该任务系统由一个执行任务的 agent 和下发任务的调度系统完成,任务调度系统中记录了所有的任务和任务下主机的时间策略。
通过任务系统,我们彻底的去掉了 db 主机上的 crontab 脚本,修改任务执行时间、策略以及是否需要执行变得轻而易举。
2、备份管理
在一期的基础上,我们完善了备份系统。通过和任务系统相结合,可以轻松的设置备份的时间以及备份的实例,是否需要备份等,保证了在业务低峰期执行备份操作。
备份操作由 agent 执行,备份成功失败通过相应的回调地址设置状态。如果一台主机上存在备份失败的实例,可以直接在备份系统中查看其备份报错日志,执行重试,省去了频繁登录 DB 主机的痛苦。
同时,备份系统每天针对核心数据库的备份执行校验操作。如果发现备份校验失败,通过告警平台触发微信或者短信的告警,方便维护人员第一时间知道是否存在备份失效的情况。
3、主机管理
主机的元数据是数据库实例的基础。在进行主机新增的时候,ZanDB 能够自动的连接 Zabbix 获取主机信息,例如磁盘大小,磁盘可用空间,内存可用空间等。
4、实例管理
为了尽可能的发挥主机的性能,我们在一台主机上部署了多个实例,因此主机和实例是一对多的关系。
通过实例管理系统,我们可以实现如下功能:
- 查看当前的实例列表,获取实例当前的数据大小,日志大小,主从状态,是否存在慢查,被 kill 的 SQL,实例历史信息性能信息等等。
- 新增单个实例,一对实例,针对一个实例 / 一对主从添加从库。新增实例的过程是通过 rsync 标准的数据库模板,然后用 my.cnf 模板渲染生成标准 my.cnf 配置文件,执行的具体步骤可以通过流程系统查看 ,支持失败重试。
- 实例的主从校验。在 MySQL 主从复制中,有可能因为主从复制错误、主从切换或者软件的 BUG 等导致主从数据不一致。为了提早发现数据的不一致,就需要每天都针对核心数据库,进行主从的一致性校验,避免产生线上影响。
- 实例拆分,用来将之前在同一个实例里面的多个 schema 拆分到不同的实例里面
- 每天将实例的元数据进行快照,如慢查数据,数据目录大小等,方便实例的历史数据分析。
5、日志管理
数据库运行最多的就是 SQL,优化 SQL 是 DBA 的职责。面对那么多的实例,如果没有一个日志系统,只能通过登录每台 DB 主机去发现慢查将是一件非常痛苦的事情。为了解放 DBA 的双手,同时更好的发现和优化慢日志,保证 DB 的稳定性,ZanDB 日志系统由此诞生。
首先实例元数据收集的过程中,会统计慢查和被 kill 的 SQL 的数据,然后更新到实例的元数据中。通过实例元数据的慢查信息,获取昨日的 TOP 慢查。
那么如何去获取慢查呢?当然要通过伟大的 agent 去获取慢查日志。慢查在每天都会进行 rotate,产生一个新的慢日志文件。系统要获取慢查详情的时候,通过调用 pt-query-digest,分析慢日志文件,将结果缓存起来,进行返回。系统下次再获取慢查的时候,如果发现该日期的慢查已经存在分析后的结果,直接返回。
同时,日志管理里面还包含了被 kill 的 SQL 的 top 情况,和慢查是类似的。
6、元数据管理
元数据管理包含了 binlog 元数据、主键的溢出校验,分片信息等。
通过 binlog 元数据管理,实现了所有实例的 binlog 信息管理。binlog 元数据记录了实例的每个 binlog 起始时间和结束时间,binlog 保留时长,在进行数据恢复的时候可以快速的定位到某个日志。
通过主键溢出校验,我们可以及时的发现哪些表的主键自增已经达到了临界值,避免因主键自增溢出无法插入导致故障。
由于交易等核心库数据量非常大,分析慢查等相关信息的时候,需要根据分片键找到对应的实例。我们开发了一个分片元数据查询功能,只要提供数据库名、分片 id 和分片数量,就可以快速的定位到一个实例,大大的方便了 DBA,实现了问题的快速定位。
7、日常维护
日常维护主要是通过 agent 执行,包括了批量执行 SQL,批量修改配置等。
批量执行 SQL 是选择一批实例,执行维护的 SQL。例如,需要修改内存中某个参数的值,或者获取参数的值。这个 SQL 只允许维护相关的,DML 是不允许执行的。
批量修改配置和执行 SQL 类型的修改配置类似,不同的是,修改配置是会同步变更配置文件,永久生效,同时也修改内存,例如调整慢查时间等。
五、展望
整套 ZanDB 系统是采用了 Python Django + Percona-Toolkit + Agent + 前端相关技术,同时利用了缓存 Redis 和 MySQL 后端 DB,整套系统采用的技术栈较简单,实现的功能对于目前来说比较实用。后续会加入数据库性能诊断,自动分析数据库慢查,获取关键信息,自动化拆库等功能。相信随着自动化的深入,DBA 的手动重复操作将越来越少,将有限的时间投入到更有价值的事情上去。