

有赞 webview 加速平台探索与建设(二)——静态资源加速
1. 综述
在前文中已讲到,有赞的 h5 页面中,静态资源分为两种,一种是有赞统一的 css/js 等资源,一种是商家端独有的商品图片等资源。
针对这两种资源类型,我们采取了不同的策略:如何发现资源变化、如何更新资源缓存?
先让我们看一下我们整体的系统运行图: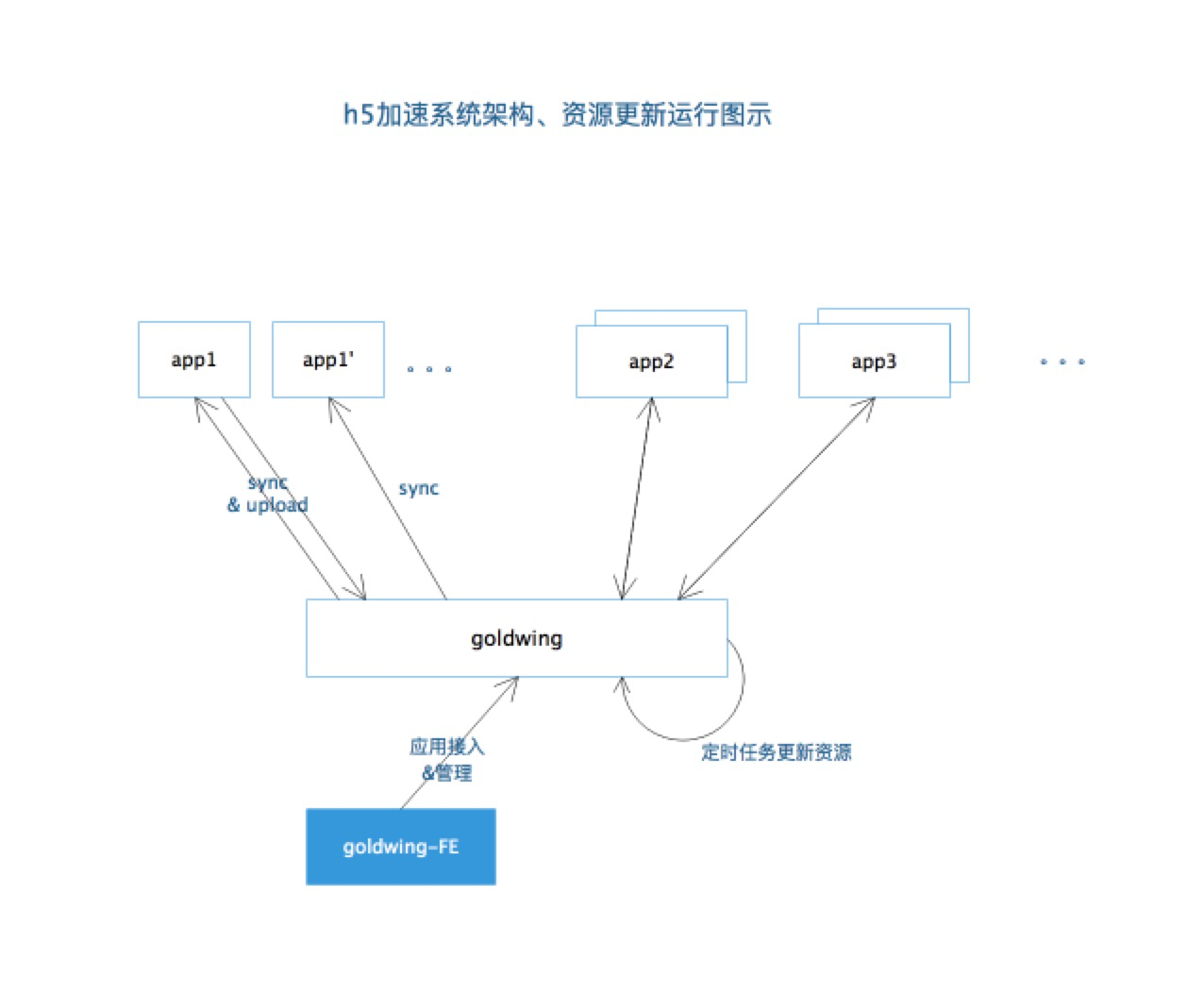
图片的上半部分描述的是商家独有的图片等资源的更新过程; 而有赞的统一的 css/js 等资源,则是采用后台定时任务来刷新,监控前端发布。
每一个静态资源(css/js/ 图片等)都会在我们的 goldwing 后台系统中生成一条数据库记录,记录它的唯一 key、路径、修改时间、所属业务、所属商家等信息。如:
每当资源变化后,根据一定的策略,都会先更新到这个数据库,客户端 APP 根据lastUpdateTime发起sync增量查询,就能拉取所有已变化的资源列表。根据这份列表将资源下载到本地,更新缓存即可。
2. 有赞统一的 css/js 等资源更新
有赞的前端一般都有固定的发布窗口,每次发布可能会引起一些 css/js 等静态资源的变更。
而所有当天的总的 css/js 资源配置都会有一个清单文件在前端指定的 git 代码库中。
根据上面的两个条件,只要在发布窗口之后,从 git 代码库读取当天最新的 css/js 资源清单文件,将每天记录与金翅数据库中已有记录做对比,更新数据即可。我们在金翅的后台做了定时任务管理,可以很方便的触发这类型的定时任务:
3. 商家端特有资源更新
对于商家端特有的图片资源(如:商品图片),并没有一个统一资源清单来记录当前最新的资源列表,也没有一个固定的时间窗口来发布这类资源(商家随时有可能上传新的商品图片)。
所以针对商家端特有资源的更新与发现,必须采用在线实时、闭环反馈的自学习方式——使金翅系统具备自动发现新资源、自动更新缓存的能力。
3.1 实时 upload 反馈系统
仔细观察金翅的系统架构与资源运行图,app1与app1'是来自同一个商家端的两个用户。
假如:现在这个商家上传了新的商品图片r1、更新了店铺的首页或者商品详情页面。 用户app1先打开了这个 h5 页面p1,那们在app1加载静态资源过程中会发现这个新的资源r1,在资源的缓存池中是不存在的。那么就有理由相信,r1可能是一个新的资源。
app1将r1上传到金翅后台,更新资源数据库。
当app1'启动,发起资源sync查询,就能将r1这个资源预先下载到自己的缓存中。当app1'真正开始加载p1这个页面,它所需要的r1这个资源,已经下载好了。
我们再来回顾上述过程,对于用户app1来讲,他其实没有获得静态资源r1的加速体验,但他发现了r1这个新资源,并把这个知识贡献给了金翅后台。
对于用户app1'来讲,他从app1的贡献受益。还有更多的类似于app1'的用户他们都从第一个发现r1这个新资源的app1这里受益。
我们有更多的像app1这样的用户,可能去发现渚如r2、r3、r4。。。这类的新资源。然后把这些新资源贡献给其他用户。我们把这类贡献知识的用户称为种子用户。
理论上来讲,只要有足够多的种子用户,遍历了这个商家端的所有页面,那么所有新的资源变化都会被发现。在此之后的所有静态资源请求,都会命中缓存。(当然,现实条件中,我们要考虑用户的网络、存储代价,并不会下载所有静态资源,也不会在非 wifi 情况下下载图片)
3.2 优质 upload 种子用户选取
我们不能让这个商家端的所有用户都能做upload操作,这不仅是浪费用户流量,也会对金翅的后台服务器造成巨大压力和许多不必要的网络请求。
比如:一个商家端有一亿个用户,难道要让这一亿个用户都去上传自己未命中的新资源吗?一个商家端一段时间内的新资源个数肯定是有限的,最多几百个而已。以一亿对几百,这样上传的资源重复率可见会有多高,根本不值得也无必要。
所以我们抽象了种子用户的概念,比如从上述商家端的一亿个用户中选择 30 个用户,他们可以上传自己发现的新资源。如果这 30 个用户选得合适,基本就可以将这个商家端所有的新资源全部找出来了,而后台的压力也大减小了。
关于种子用户的选择策略,首先得清楚,什么类型的种子用户算是比较优质的?那些经常打开页面、页面路径进入得比较深的就是合适的优质种子用户来源。完全可能根据这个特点选取新的种子用户,淘汰旧的种子用户。
我们在金翅的后台系统中,对种子用户会下发一个证书,作为种子用户的标识。这个证书的字段包括:用户端的 uuid、生成时间、过期时间等。金翅客户端根据这个证书的有无及有效性来判断是否可以上传未命中的新资源。证书的下发是随着资源sync接口一起返回的,因为每个用户都需要调用sync,省去一次网络请求。
3.3 upload 页面范围控制
我们不能对所有的页面做上述upload策略,因为有许多页面是用户独有的、隐私的。比如:客服聊天面、购物车、订单页。这些页面里的图片等静态资源只有这个用户才有。
所有upload模块需要对页面做一些限制,只有满足条件的页面才能执行。
有赞的页面链接中,可以根据页面链接的模式来判断是什么页面类型。比如:店铺主页一定会匹配(?<=v2\/showcase\/homepage\?).*alias=(\w+) 模式,商品详情页则会匹配(?<=v2\/goods\/)(\w+)。只有当前页面链接能够匹配限定的模式才能执行upload策略。
在金翅的管理控制台可以动态的配置upload开关及允许upload的 url 链接模式:
上述配置实际允许了店铺首页 / 微页面、商品详情等页面。
3.4 未命中资源流处理
对于未命中的资源,还有两个问题要处理。
- 当调用
WebViewClient.shouldInterceptRequest(view, url)要求加载链接为url的这个资源时,本地资源缓存中没有,咋办?
直接返回null,让WebView自己去下载?然后为了下次缓存能够命中,在 native 端再去下载一份放到缓存中?两倍的流量消耗!
为了减少流量消耗,我们采用 native 代理 webview 请求的方案,在代理过程中将缓存写入磁盘
在 Android 端我们使用OkHttp或URLConnection代理这个url资源的请求,构造inpustream wrapper, 一边向WebView返回数据流,一边将文件写到本地缓存中。
在 iOS 端我们使用 NSURLProtocol 代理 WebView 中的资源请求,在将 data 返回给 client 的同时,写入本地文件。
public class InputStreamWrapper extends InputStream {
private InputStream inputStream; // 从OkHttp获取的资源文件网络输入流
private FileOutputStream storingOutputStream; // 要存入的本地缓存文件输出流
@Override
public int read(final byte[] b, int off, int len) throws IOException {
int c = inputStream.read(b, off, len);
if (c != -1) {
storingOutputStream.write(b, off, c);
}
return c;
}
@Override
public void close() throws IOException {
super.close();
int bufLen = 4096;
byte[] buf = new byte[bufLen];
int c;
// the stream may have not been read to end
// 注:对于一些大的资源文件(300k以上),
// 从WebView调过来的read方法可能未读完所有数据,这里需要确保将网络输入流读完。
// 防止写到本地的资源不完整,造成加载错误。
while((c = inputStream.read(buf, 0, bufLen)) != -1) {
storingOutputStream.write(buf, 0, c);
}
inputStream.close()
storingOutputStream.close();
storingOutputStream = null;
}
}
这里对页面加载性能影响是比较小的,因为read()和close()方法都是在WebView的子线程中完成,往文件流写的操作也是异步的。
- 第二个问题,如果未命中的资源,也采用了上述 stream 引流的方式,假如这个资源是个文本资源,但它的字符编码不是默认的 UTF-8?
当然可以将此资源所有文本内容下载完后再整体转码再交给WebView,但这就丧失了WebView流式渐进解析的优势。
我们采用了将网络输入流InputStream和输出流(缓存文件及WebView端读取)做了一次转接,套在PipedOutputStream和PipedInputStream两端,将网络输入流读入,转换成 UTF-8 编码,再通过PipedOutputStream输出给PipedInputStream交给WebView读取。
4. 资源清理——LRU 队列
在资源缓存中,缓存数据占用的存储超过预先设定值时,我们采用了最近使用的 LRU 队列来淘汰老的资源。确保我们的资源缓存足够轻巧、有效!
并且,css/js 等资源与图片资源是在两个分开的 LRU 队列中。因为它们的大小、数量、更新速度差异较大。分开维护,以免将一些重要的资源挤掉。
5. 命中率与白屏时间——埋点与统计
当系统上线之后,怎么知道系统运行的好坏?我们对资源命中率及白屏时间做了统计。
资源命中率的计算倒好说,当前加载的页面,命中了多少,未命中的多少。一清二白,很好计算。
对于白屏时间的统计就要麻烦得多了,先看下图: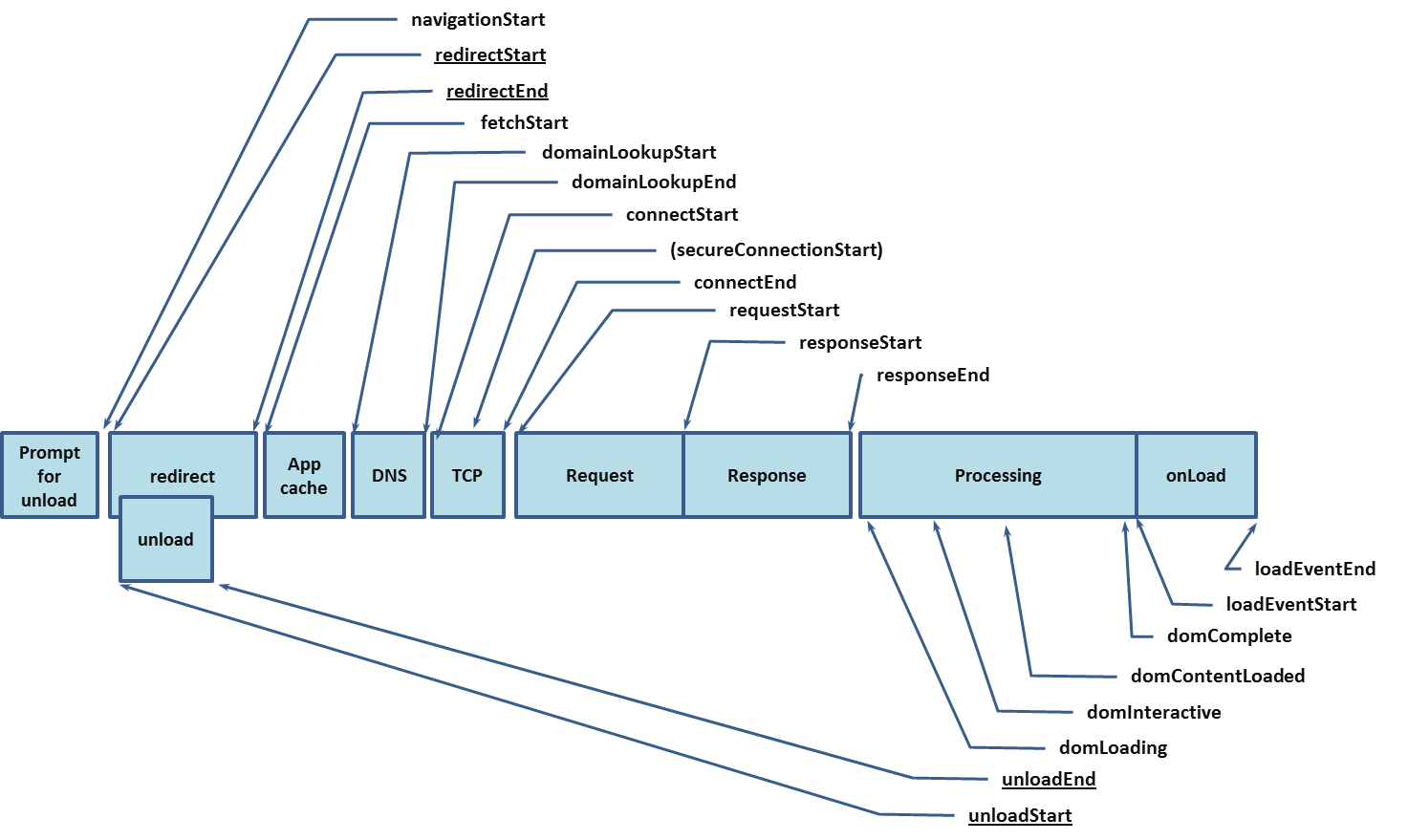
这是一个 html 加载解析的全过程、各个阶段。在WebView的window.performance.timing对象中,包含上述所有字段的属性值。各阶段的口径定义如下:
通过 jsbridge 方法读取到window.performance.timing对象后,将responseStart-navigationStart计为白屏时间。
6. 总结
有赞的静态资源的缓存设计是相当复杂的!要处理实时、及商家端特有性等诸多问题。更考虑到了资源缓存的发现、生成、统计、清理等完整的生命周期,及 stream 引流优化等。
这套静态资源缓存体系,即解决了二次及以后打开 页面的资源命中问题,也解决首次打开的命中,完整提升资源命中率。
借助静态资源缓存链路的建设,我们将金翅的移动端、java 后端、nodejs 管理端全平台都搭建起来了。为实现 html 的加速、动态化配置管理、应用接入建立了良好的根基。