

Flink 滑动窗口优化
一、前言
Flink 的窗口功能非常强大,因为要支持各种各样的窗口,像滑动窗口和滚动窗口这样的对齐窗口,像会话窗口这样的非对齐窗口,复杂度也会比较高。其中在超长滑动窗口的性能上也不尽如人意。这篇文章首先会阐述为什么在超长滑动窗口下 Flink 的性能会降级的很严重,以及在有赞我们是如何解决这个问题的。此外,在优化中并没有去兼顾 Evictor 的逻辑,因为在业务中并没有相应的需求。
二、Flink 滑动窗口的实现
Flink Window 算子的整体概念如下图所示,可以看到有几个重要的部分,首先是 WindowAssigner 和 Trigger,还有 Evaluation Function (也就是用户定义的对窗口内元素的计算方式),Evictor 与本次优化关系不大,不会展开。
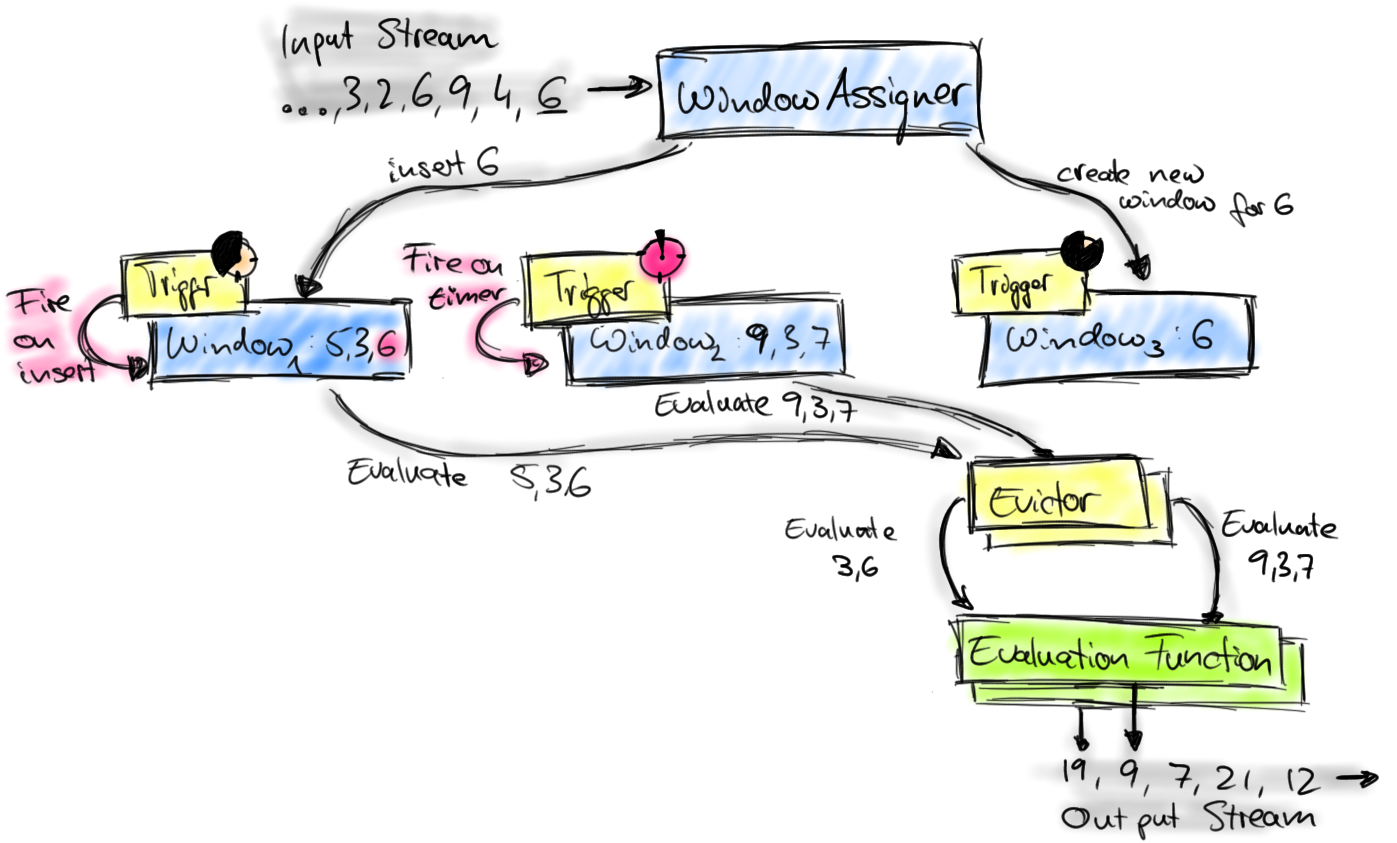
2.1 WindowAssigner
WindowAssigner 抽象类有一个关键的抽象方法就是 assignWindows,根据一个元素分配它所属的窗口。
// 返回该元素应该被分配的窗口的集合。
public abstract Collection<W> assignWindows(T element, long timestamp, WindowAssignerContext context);
对于滑动窗口来说,如下图所示,每个元素可能属于多个窗口。这个数量也可以由 n = 窗口长度 / 滑动步长 计算出来,范围在 [n, n+1]。
此处使用 SlidingEventTimeWindows 来举例,它的 assignWindows 实现如下,针对输入的元素和它绑定的 timestamp,计算出该元素所属的每一个窗口。
@Override
public Collection<TimeWindow> assignWindows(Object element, long timestamp, WindowAssignerContext context) {
if (timestamp > Long.MIN_VALUE) {
List<TimeWindow> windows = new ArrayList<>((int) (size / slide));
long lastStart = TimeWindow.getWindowStartWithOffset(timestamp, offset, slide);
for (long start = lastStart;
start > timestamp - size;
start -= slide) {
windows.add(new TimeWindow(start, start + size));
}
return windows;
} else {
throw new RuntimeException("Record has Long.MIN_VALUE timestamp (= no timestamp marker). " +
"Is the time characteristic set to 'ProcessingTime', or did you forget to call " +
"'DataStream.assignTimestampsAndWatermarks(...)'?");
}
}
2.2 Trigger 抽象类
对于 Trigger 来说,有三个很重要的方法,如下:
// 针对流入的每一个元素的每一个所属的窗口,会调用该方法,返回 Trigger 结果。
public abstract TriggerResult onElement(T element, long timestamp, W window, TriggerContext ctx) throws Exception;
// 当处理时间到达了注册的计时器的时间时,会调用该方法,返回 Trigger 结果。
public abstract TriggerResult onProcessingTime(long time, W window, TriggerContext ctx) throws Exception;
// 当事件时间到达了注册的计时器的时间时,会调用该方法,返回 Trigger 结果。
public abstract TriggerResult onEventTime(long time, W window, TriggerContext ctx) throws Exception;
而 EventTimeTrigger 的实现如下,当 onElement 被调用时,如果 watermark 已经超过了 window 的话会直接返回 Fire,不然的话会将 window 的最大时间戳注册到定时器中。 当 onEventTime 被调用时,会比较这个定时器注册的时间和当前 window 最大时间戳,只有等于的情况下才会 Fire。因为是事件时间的 Trigger,所以 onProcessingTime 没有作为,事实上这个 Code Path 也不应该被调用到。
@Override
public TriggerResult onElement(Object element, long timestamp, TimeWindow window, TriggerContext ctx) throws Exception {
if (window.maxTimestamp() <= ctx.getCurrentWatermark()) {
// if the watermark is already past the window fire immediately
return TriggerResult.FIRE;
} else {
ctx.registerEventTimeTimer(window.maxTimestamp());
return TriggerResult.CONTINUE;
}
}
@Override
public TriggerResult onEventTime(long time, TimeWindow window, TriggerContext ctx) {
return time == window.maxTimestamp() ?
TriggerResult.FIRE :
TriggerResult.CONTINUE;
}
@Override
public TriggerResult onProcessingTime(long time, TimeWindow window, TriggerContext ctx) throws Exception {
return TriggerResult.CONTINUE;
}
2.3 WindowOperator
当一条数据进入到 WindowOperator,首先会通过 WindowAssigner 获取它所属的所有窗口的集合,在非 MergingWindowAssigner(SessionWindow) 的情况下,会对这条数据所属的窗口集合进行遍历,操作如下:
for (W window: elementWindows) {
// drop if the window is already late
if (isWindowLate(window)) {
continue;
}
isSkippedElement = false;
windowState.setCurrentNamespace(window);
windowState.add(element.getValue());
triggerContext.key = key;
triggerContext.window = window;
TriggerResult triggerResult = triggerContext.onElement(element);
if (triggerResult.isFire()) {
ACC contents = windowState.get();
if (contents == null) {
continue;
}
emitWindowContents(window, contents);
}
if (triggerResult.isPurge()) {
windowState.clear();
}
registerCleanupTimer(window);
}
首先判断这个窗口是否过期了,当这个窗口已经被清理过的话,就会直接跳过。
接下来把 windowState 切换到这个窗口的 namespace 下,并且调用 TriggerContext 的 onElement 方法,这个方法接下来会调用用户定义的 Trigger 的 onElement 方法。事实上如果是 EventTimeTrigger 的话,只有当 Window 已经被 Watermark 超过时才会返回 Fire。最后为这个 窗口注册一个清理的定时器。
三、超长滑动窗口场景的性能问题及解决方案
3.1 问题一 - 状态写入
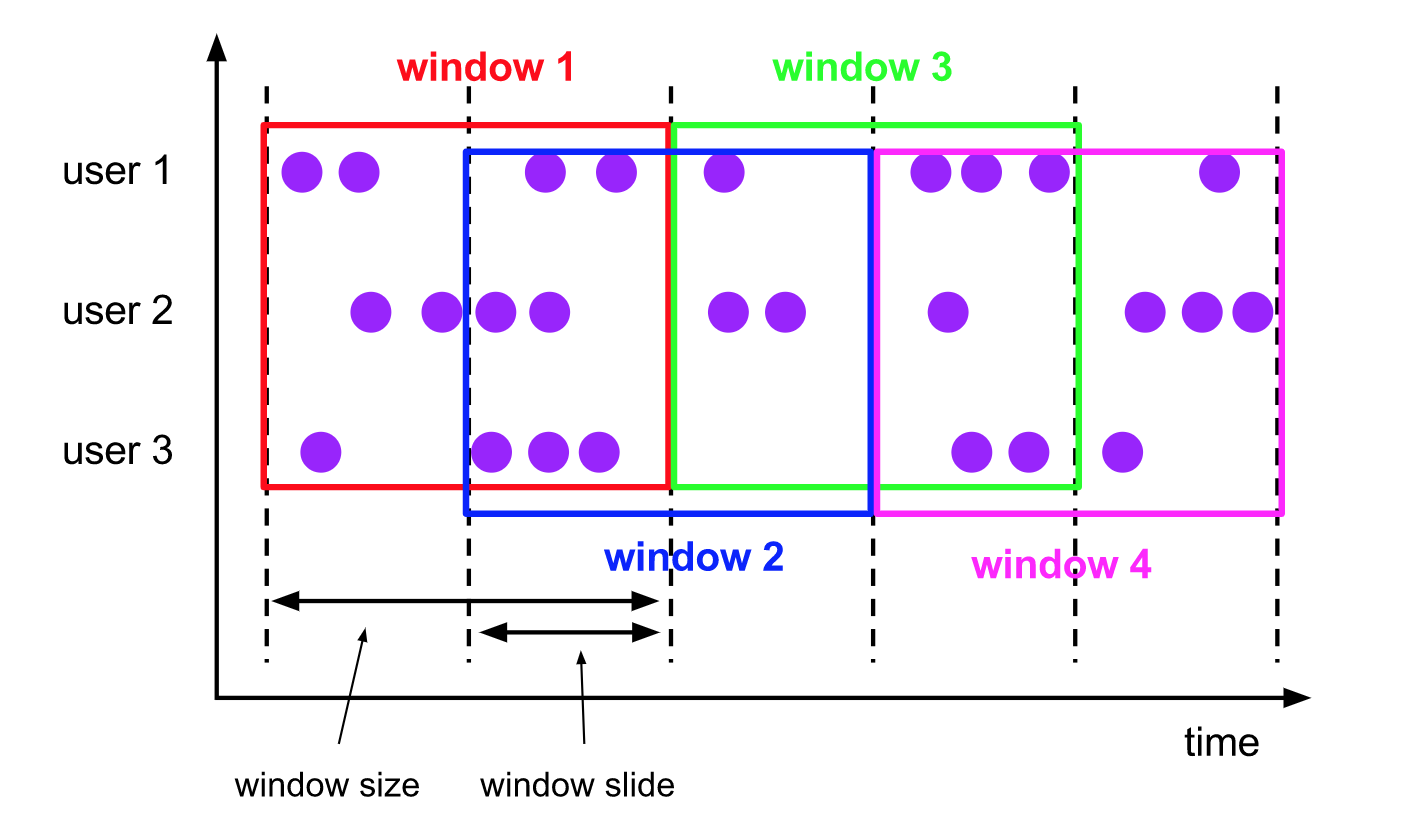
首先是吞吐量,因为使用了 RocksDB 作为 Statebackend,所以写入和读取的速度都不会像在堆内那么快。下图是在窗口长度为步长的两倍情况下,每个元素都会属于两个窗口,而 Flink 的窗口算子会将每一个元素分别写入到每一个所属的 key window 组合对应的状态中 (Window 5 不在图中)。
上图中的开销还不是那么明显,例如在一小时窗口长度和五分钟步长的情况下,针对每一个元素,需要遍历 288 个窗口并往对应的 State 写入数据,在窗口算子中,开销最大的往往就是对 State 的读写。所以同一个操作相比于滚动窗口,吞吐量下滑在 288 倍以上。
3.2 问题二 - 定时器
就像上图中所示,因为每个 key Window 对都对应一个 State,所以它们需要知道什么时候触发输出和清除,这个就需要依赖于定时器。
在 Flink 的实现中,基于 RocksDB 实现了一个定时器的最小堆,这个最小堆是根据定时器的注册时间排序的并且可以去重,时间小的会被先 pop 出来。并且这个堆由 InternalTimerServiceManager 来管理的。
例如在事件时间下,每个算子会将介绍到的 Watermark 与当前的 WaterMark 进行比较,当 Watermark 的值更新后,会调用 InternalTimerServiceManager 的 advanceWatermark 方法。这个方法会将定时器的最小堆中所有时间小于 Watermark 的定时器全都 pop 出来,并且调用 WindowOperator 的 onEventTime 方法 (上文中已有介绍)。
在窗口算子的实现中,针对每一个 key window 对,需要至少注册一个触发输出的定时器和一个清理窗口状态的计时器 (因为有 allowLateness 这个 API)。虽然定时器可以去重,但是同样去重也会需要对状态的读取成本。由于定时器的读取与写入相对于 State 来说成本较低,但是还是对吞吐量有降级。
3.3 解决方案
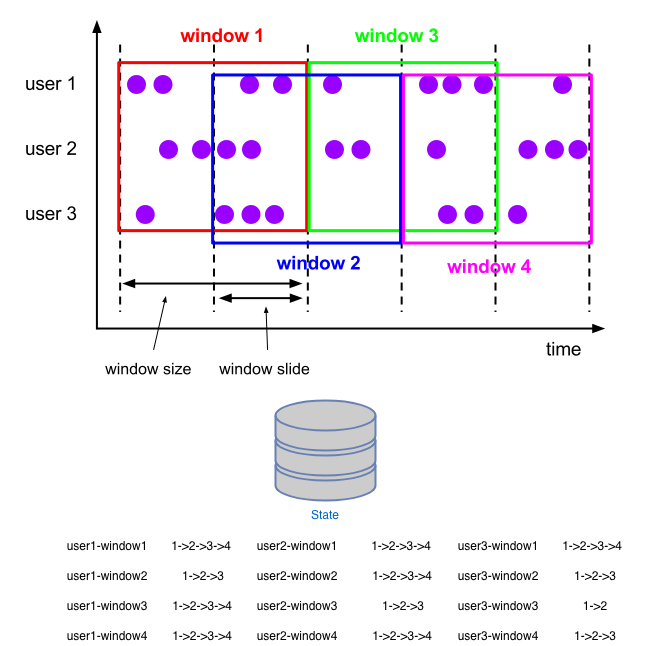
首先针对问题一,如何去减少 n (窗口长度与滑动步长的比值) 倍的状态读写,可以通过时间分片的方法。对于滑动窗口这样的对齐窗口,其实是有很多重叠的区域。而且从业务的视角来看,往往窗口的长度是可以被步长所整除的,那么第一件事就是要找到窗口长度和窗口步长的最小公约数。例如下图窗口长度是滑动步长两倍的滑动窗口,这个公约数就是滑动步长,在这里我叫它们重叠窗口。
通过将元素存入重叠窗口,保证了每个元素在进入窗口算子时只会更新一个重叠窗口 (对于聚合状态此处相当于根据重叠窗口做预聚合)。下图可以看到虽然对于存储来说 key 的数量是一样的,但是状态的写入少了一半。如果这个状态还不是聚合状态的话,那 checkpoint 的成本也会降低很多。
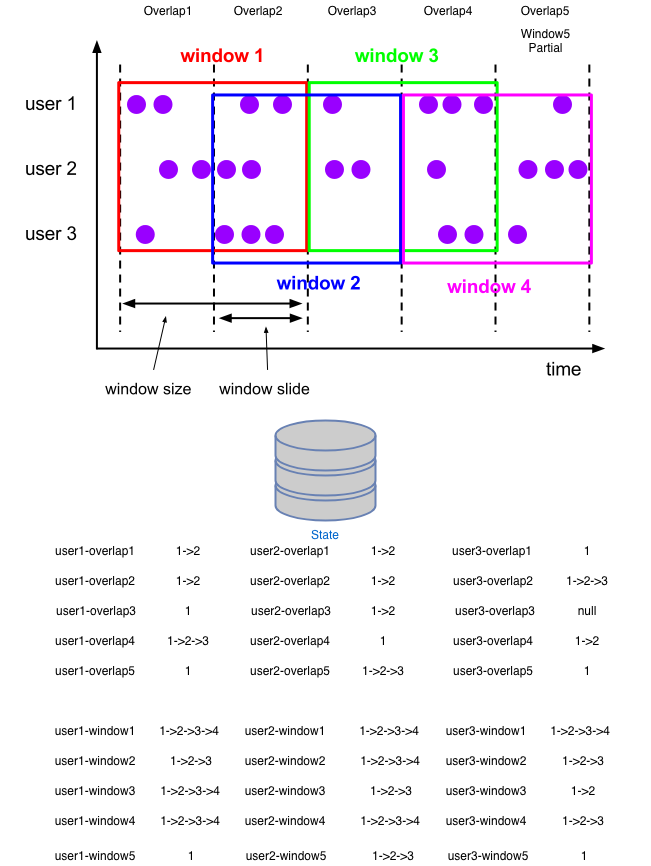
对于写入成本降低 n 倍事实上不难理解,但是读就比较复杂了,因为读的次数不止取决于数据的数量,还取决于每个 key 下数据的分布。
乍一眼看,在输出的时候,读的成本事实上是增加的。对于同样的数据集来说,它们触发的窗口输出也是相同的。而且优化前是读的完全聚合的状态或者是完整的状态集合,而现在输出的时候只能获取到按重叠窗口预聚合的结果,需要去获取所有重叠窗口的结果再做一次聚合。可能说到这大家会觉得对于 RocksDB 这种采用 LSM 树作为存储引擎的数据库来说读的成本(没有命中缓存的情况下)比写的成本还要高。
但是对于聚合的结果更新而言,是会有三个操作,读,聚合,写,这三个操作是会随着 n 和吞吐量倍增。而对于重叠窗口的方式就比较复杂,它受到每个 key 的数据的分布的影响更多,接下来从三种分布来分析比较优化前和优化后读取的次数。
3.3.1 密集分布
对于一个 key 的密集分布,这样的场景有很多,比如在电商中,对于一个比较火热的店铺统计访问人数,假如说这个窗口不是特别小,即使是分钟级,那么每个重叠的窗口都会有不止一条数据。
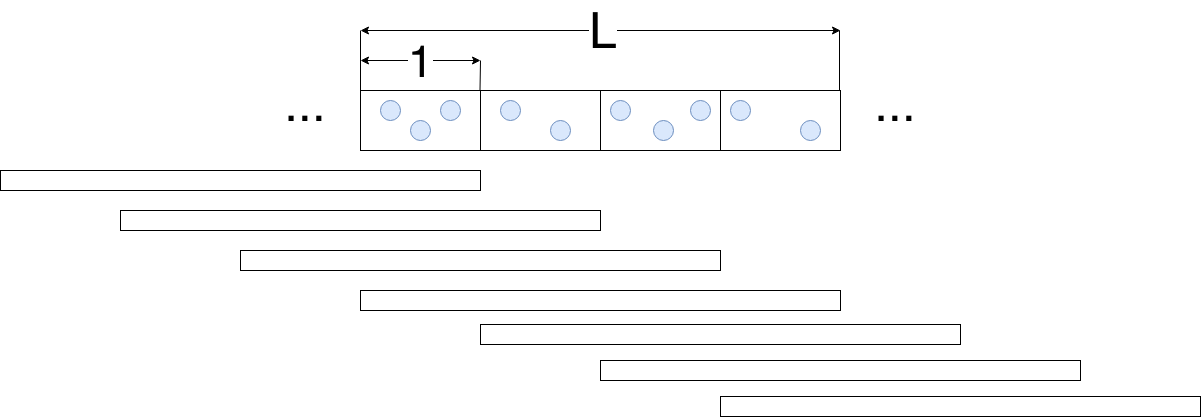
我们此处定义重叠窗口长度为 1 (时间单位可以是任意), 窗口总长度为 L,每个重叠窗口中数据的平均数量为 a (例如在上图 a 的值为 2.5)。
由于状态更新是是先写入后读取的,在优化后,每个消息都会对应一次读取,在这段时间内会有读取次数为
L * a
而优化前由于要针对每一个输入的窗口各更新一次,读取次数为
L * L * a = L ^ 2 * a
那在这段时间内到底有多少次窗口输出触发了状态的读取呢?乍一看在图中 L 为 4,2L - 1 (7) 个窗口需要读取重叠窗口中的状态。优化后的窗口输出时总共涉及到了的状态读取次数为
(1 + ... + (L - 1)) * 2 + L = L * (L - 1) / 2 * 2 + L = L ^ 2
而在优化前,这些窗口输出时只需要读一次状态,并且由于前后分布相同的缘故,事实上对于这一批数据等价于 L 次状态读取。
所以总的代价是优化之后和之前分别为
优化后 = L ^ 2 + L * a
优化前 = L ^ 2 * a + L
Delta = (1 - a)* (L - 1)* L
因为是密集场景,根据我们之前的假设,a 必然大于 1, 因为是滑动窗口, L 也必然大于 1,Delta 必然是小于 0 的。
所以在窗口与步长比例越高的情况下,读优化的数量会接近平方增长。
或者是在每个重叠窗口内数据越多的情况下 (数据越密集),读优化的数量会接近线性增长。
3.3.2 稀疏分布
对于 Key 的稀疏分布,很有可能是某个用户的行为,往往是在短时间内 (一个或少数几个重叠窗口内) 做统计。为了简化逻辑,这里的稀疏分布假设数据只会出现在一个重叠窗口之内, 并且在前后接近一个窗口的时间内都不会出现。
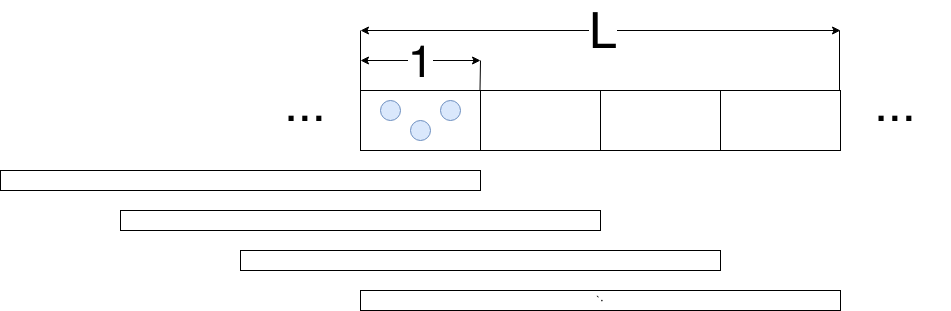
定义在这个窗口内数据的个数为 a。
状态更新时的读取很容易可以得出,优化前后分别为
优化前 = L * a
优化后 = a
而输出时候的读取只会影响到 L 个窗口,优化前后分别为,根据规律,发现非零读取的总数约等于 1 + … + 1 + 2 + … + 2 + … + m 总共有 2 * L - 1 个数
优化前 = L
优化后 ≈ (2 * L - 1) * (1 + m) / 2 + ≈ L * m
乍一看优化后成本增加了许多,但由于每一次窗口输出的时候只有一个重叠窗口是有状态的,L - 1 个重叠窗口的都为空,根据 RocksDB 的设计,可以借助到 Bloom Filter。Bloom Filter 判断元素不在集合,那肯定不在。如果判断元素存在集合中,有一定的概率判断错误。这里假设一个系数为 K,K 表示没有 BloomFilter 的情况下空状态读取的成本除以借助 BloomFilter 后空状态读取的成本的比例。
优化后的成本就变成了
L + L * (L - 1) / K 约等于 L + L * (L / K)
优化前减优化后也就等于
L * (a - L / K)
在 K 可能为常量(并且大于 1)的情况下,优化后窗口长度与步长比例越大,成本越高,稀疏窗口中的消息条数越多,成本就会降低。但是可以看出来在这种情况下对读优化是不明显的,甚至会起到反效果,但是由于写次数上还有从 L * L * a 降到了 L * a。加入引入另一个系数 D,读状态的成本除以的写状态的成本。优化前后的总成本差值为
L * (a - L / K) + L * a * (L - 1) / D ≈ L * (a - L / K) + L * L * a / D = L * (a + L * (a / D - 1 / K))
这里头涉及的变量太多,但是假如读成本是写成本的十倍,BloomFilter 将读空值的成本降低 10 倍。那么在最差的情况下,只有一条数据,那么总成本还是会降低一些。
3.3.3 数据定期批量出现
这种情形更像是监控的数据。假设每 L 的时间中会有 m 个重叠窗口有数据,并且每个重叠窗口有 a 条数据。
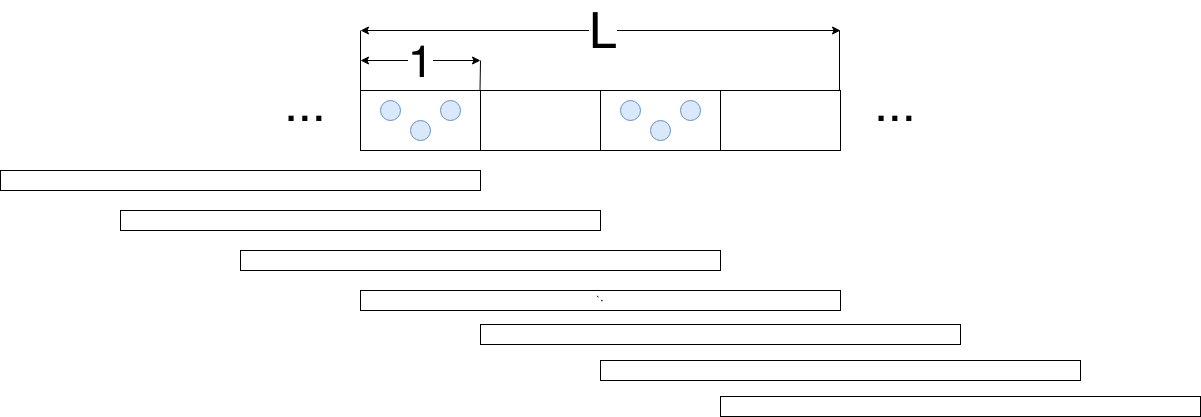
优化前的数据读取依旧很容易得出为
L * m * a + L
而优化后的读取成本比较难以估计,由于前后分布相同,我们只计算从这个时间阶段开始以后的窗口对状态的读取。所以读取的总状态次数为 (1 + … + L),非空状态次数约为 L * (1 + m) / 2, 空状态约为 L * (L - m + 1) / 2, (这两者加起来略大于总的状态读取数,不过可以忽略) 所以总成本约为
L * (1 + m) / 2 + (L - m + 1) / 2K + m * a
为了简化计算尝试省去常数项,假设 m >> 1 并且 (L - m) >> 1,就变成
L * m / 2 + (L - m) / 2K + m * a
前后的差值约为
L / 2 * ( 2 * m * a - m - (L - m) / 2K) - L - ma
假设 a 分别为 1 和 100
L / 2 * (m - (L - m) / 2K) - L - m
L / 2 * (99 * m - (L - m) / 2K) - L - 100 * m
可以看出来在 L 比较大的情形下, a 越大,m 越大读成本优化越明显。
3.4 其他场景
接下来从读的角度举两个比较极端的例子 (不考虑缓存命中的情况下):
首先是一些变量的命名,当窗口长度与滑动步长的比值为 n 时,假设总共处理的时间为 m 个窗口步长,一个窗口步长的时间内总共处理的数据 T,key 的数量 K。
例子一:假设这些 Key 全部都平均分布到了各个步长中.
使用 Flink 本身的滑动窗口来处理的话,当所有消息刚进入时,因为要更新状态,所以会有 n * m * T 的读取。最后当输出的时候会对每个 key 和 Window 对触发,也就是 m * K 的状态读取,总共加起来就是 n * m * T + m * K 次读取。
而当使用重叠窗口的方法优化时,每条消息消息进入系统,只会对重叠窗口进行一次更新,也就是 m * T 次读取。而当每个 key 和 window 对的触发输出,都会有 n 个重叠窗口的状态读取,也就是 n * m * K,总共就是 n * m * K + m * T。将优化前读取次数减去优化后,可以得到的是
Delta = n * m * (T - K) + m * (K - T) = m * (n - 1) * (T - K) ≈ m * n * (T - K)
因为前面的假设这些 Key 全部平分到了各个步长中,所以 T 是大于 K 的,优化后读取次数明显减少。
例子二: 现实中的另一种情况就是这些 key 是稀疏的,那上述的公式也就不成立了。
此处假设变了,每个 key 只会出现在 1 个步长中,还可以知道 1 << n。过程这里就不赘述了,最后 flink 自带的滑窗,至多会有 n * m * T + n * K,而对于优化之后,则变成了 m * T + n * n * K。
单看后半部分,已经随着 n 做平方级的增长了,看起来性能会有很大的下滑。
但是可以将这儿再拆一下,变成 m * T + n * (1 + (n - 1)) * K,此处的意义在与在每次窗口触发输出是,只有 1 个重叠窗口是有值得,另外 (n - 1) 个重叠窗口是空的,根据 RocksDB 的设计,可以借助到 Bloom Filter。Bloom Filter 判断元素不在集合,那肯定不在。如果判断元素存在集合中,有一定的概率判断错误。
而其中的 (n - 1) 个重叠窗口读的大部分都能够被 BloomFilter 给过滤掉,成本很低。而 1 又远小于 n。如果我们引入一个系数,这个系数 L 表示的是经过 Bloom Filter 优化后对空的重叠窗口的读成本的比例的话(L 的系数比较难以确定),
所以最后得到的公式是 m * T + n * K + n * (n - 1) * K * L 约等于 m * T + n * K + n * n * K * L。
将优化前减去优化后,得到的是
(n - 1) * m * T - n * n * K * L ≈ n * (m * T - n * K * L)
m * T 是总数据量, m * T > K 是确定的,n * L 同时取决于比值和 Bloom Filter 的效率。
现实的情况往往是例子一和例子二的综合,有热点,大部分又是稀疏的,再加上又有缓存的存在,并且优化后总的状态的量被减少了很多,再加上写被大大减少了,所以总体性能是有提升的,但是也会取决于用户的场景。
针对问题二,其实并没有特别好的优化方案。但是因为用户在用 Flink 的 SQL 来做实时任务时,其实大部分情况下是不会配置 allowLateness 的,也就是说输出和清理状态可以用同一个定时器来触发,所以当判断到 allowLateness 为 0 时,只注册一个定时器,可以将定时器的写入成本最多降低到一半。
3.5 相关工作
Flink 社区也曾经提出过类似的方案 (FLINK-7001), 但是没有合入. 对于这种长窗口的情况,这并不是一个最优雅的解决方案,只能算是一个 Work Around。对于业务方来说,真正的诉求应该是实时的获取截止到当前的一个时间段内的统计数据.
在有赞, 除了在 Flink 引擎做优化意外, 目前还在朝着两个方向:
- 借助 Druid 这个预聚合的实时 olap 解决方案;
- 利用 Flink 实现实时指标服务, 基本思想也是预聚合的思想, 将细粒度结果存储在在线存储中, 做读时聚合.
Druid 方案目前还存在着整点读 RT 抖动和平均 RT 过长的问题, 对于 RT 敏感的应用场景, 没办法很好满足.
实时指标服务方案还在构建中, 初步想法是抽象实时指标转化为 Flink 实时任务, 将细粒度实时指标结果写入 在线存储 (HBase, Redis) 中, 最后做读时聚合. 方案的最终效果, 还要待上线后验证.
四、小结
这次优化事实上效果会取决多个因素,从线上实际效果看, 视重叠系数的不同,性能上有 3~8 倍的优化.
最后打个小广告,有赞大数据团队基础设施团队,主要负责有赞的数据平台(DP), 实时计算 (Storm, Spark Streaming, Flink),离线计算 (HDFS,YARN,HIVE, SPARK SQL),在线存储(HBase),实时 OLAP(Druid) 等数个技术产品,欢迎感兴趣的小伙伴联系 hefei@youzan.com